8비트 MSX로 컴퓨터를 배웠으나 나의 첫 컴퓨터는 IBM XT였고, 꽤 오랜 기간 DOS를 사용했다. 그래서인지 아직도 배치하면 AUTOEXEC.BAT가 같이 생각난다. 이번에 정리할 내용은 많이 사용하는 스프링 배치의 성능 개선에 대한 것이다.
배경
백엔드 서비스를 운영하는 개발팀은 이미 다양한 배치를 운영하고 있을 것이고, 스프링 배치로 구현되었을 확률이 높다. 많은 배치는 서비스 사용량이 적은 새벽에 실행되고, 서비스가 작을 때는 성능에 민감하지 않아도 괜찮다. 하지만, 서비스가 커지고 배치가 처리해야 하는 데이터의 양이 증가하면서 배치의 실행 시간도 같이 증가할 것이다. 예를 들어 매일 새벽 3시에 시작하는 배치의 실행 시간이 점진적으로 증가하여 9시까지 실행되고 있다면 문제가 될 수 있고, 1시간 주기로 실행되는 배치의 실행 시간이 증가하여 1시간을 넘기면 문제가 된다. 즉, 성능을 개선해야 할 필요가 생긴 것이다. 글의 말미에서 성능 차이를 확인한다.
예제
많은 스프링 배치 예제가 배치 설명에 집중하기 위해 다루기 간편한 파일을 대상으로 I/O를 구성하고 인메모리 데이터 변환 정도로 예제를 구성한다. 하지만, 실무에서는 여러 데이터베이스와 외부 API를 사용하며 실행되는 배치들도 많다. DB를 대상으로 배치를 구성하면 배치의 성능을 개선했을 때 DB의 성능 그래프가 다르게 그려지는 것을 시각적으로 간단히 확인할 수 있다는 장점도 있다. 아래에서 볼 것이다. 이번 포스팅에서 다루는 내용의 프로젝트는 예제 치고는 크지만, 실무에서 자주 볼 수 있는 구성으로 만들었고 아래와 같다.
프로젝트 구성
- MySQL 8.3 - Docker Compose 3.1
- Source Database - UserNames
- Target Database - Nicknames
- Spring Boot Web 2.7
- Nickname Generator API Server
- Spring Batch 4.3 - Spring Boot 2.7
- DBInitializerBatch
- MigrationBatch
코드는 모두 GitHub에 올라가 있다.
SpringBatchMultiThreadedPartitions Repository에는 2개의 Batch의 코드와 Docker Compose 구성이 있다.
NicknameGeneratorAPI Repository에는 API 서버의 코드가 있다.
이 글에서 다루는 범위
배치 예제치고는 프로젝트 구성이 복잡해진 만큼 사용된 기술 스택이 많아졌다. 이 글을 읽는 데 필요한 배경지식으로 Java, Multi Thread, Spring Framework, Spring Batch, JPA, REST API, Docker Compose, Gradle에 대한 기본적인 내용을 이해하고 있으며 Docker Compose는 설치되어 있다고 가정한다. NicknameGeneratorAPI에 대한 내용은 설명하지 않고, JPA 관련 설명도 하지 않는다. SpringBatchMultiThreadedPartitions 예제에서 job 패키지에 대한 부분을 전체가 아닌 코드 조각을 가지고 중요한 부분만 설명하는 정도로 정리한다. 2개의 예제 프로젝트에는 21개의 테스트가 준비되어 있으니 참고 바란다.
환경 설정
코드에 대한 이야기를 하기 전에 배치를 실행할 수 있도록 환경 설정을 먼저 하자.
API Server 준비
NicknameGeneratorAPI를 체크아웃 받고, 체크아웃 받은 디렉터리로 이동한다.
아래와 같이 API Server를 쉽게 종료할 수 있도록 Gradle을 사용하여 API Server를 Foreground로 실행한다.
% ./gradlew bootRun
NicknameGeneratorAPI에 대한 설명을 생략하지만, 코드가 길지 않고 단위 테스트가 준비되어 있으니, 코드를 파악하기는 쉬울 것이다.

Database 준비
새로운 터미널을 열어서 SpringBatchMultiThreadedPartitions Repo를 체크아웃 받고, 체크아웃 받은 디렉터리로 이동한다.
아래와 같이 Docker Compose와 Gradle을 사용하여 로컬에 2개의 DB를 컨테이너로 실행하고, DB를 초기화한다.
DB Server 실행
% docker-compose -f docker/docker-compose.yml up -d
DB 초기화
% ./gradlew bootRun --args='--spring.batch.job.names=DBInitializerJob'
DB 마이그레이션
% ./gradlew bootRun --args='--spring.batch.job.names=MigrationJob'
MigrationJob 배치까지 정상 실행되었다면 환경 검증은 완료한 것이다. 참고로, NicknameGeneratorAPI는 5ms의 응답 지연을 강제하고 있다. IntelliJ에서 예제의 실행을 간소화하려고 잡 파라미터 입력 대신 @Value를 사용한 Property Injection을 사용했다.
스프링 배치의 파티셔닝
스프링 배치에서 제공하는 파티셔너의 개념을 간단히 소개하면, 큰 범위를 커버하는 하나의 스탭을 여러 개의 작은 범위를 커버하는 서브 스탭으로 나누어서 실행하여 성능 향상을 기대한다. 이때 각 서브 스탭은 별도의 스레드에서 실행되며 각 서브 스탭은 완전한 스탭과 동일하게 동작한다. 파티셔닝을 사용할 수 있는지는 배치가 커버할 데이터를 나눌 수 있는가와 이렇게 나누어진 데이터가 독립적으로 처리될 수 있는가에 따라서 갈린다.
이 조건을 만족하는 데이터라면 단순히 같은 배치 잡을 여러 개 실행해도 되지 않을까? 물론, 매번 각 배치 잡의 실행 파라미터로 직접 데이터를 나누어서 넣고 실행한다면 파티셔닝과 비슷하게 여러 개의 스탭이 병렬로 실행된다. 다만, 각 스탭만 실행되는 것이 아니라 잡 자체가 별도의 JVM 프로세스로 무겁게 실행되고 일부 잡이 실패한다면 개별적으로 직접 재실행해 줘야 한다.
파티셔닝 잡의 경우는 잡을 재실행하면 실패한 서브 스탭만 이어서 실행될 것이다. 물론, 이 동작은 여러 조건과 설정 상태에 따라 다르다. 또한, 데이터를 나누는 작업을 Partitioner 인터페이스를 구현하여 자동화할 수 있기에 매번 직접 데이터를 나누어서 각 잡을 별도로 실행하지 않아도 되고 각 서브 스탭은 프로세스보다 가벼운 스레드로 분리되어 실행된다. 로컬 파니셔닝에 대해서 다루는 만큼 헷갈릴 수 있는 grid 용어 사용을 글과 예제에서 배제했다.
더 자세한 설명은 https://www.baeldung.com/spring-batch-partitioner 과 글의 말미에 소개하는 책을 참고 바란다.
멀티 스레드
자바에서는 CompletableFuture를 사용하여 간단히 멀티 스레드를 사용할 수 있다. 이 예제에서는 파티셔너를 사용하여 이미 멀티 스레드 기반의 병렬 작업이 진행되는데 CompletableFuture를 이용한 멀티 스레드를 추가로 사용하는 이유는 ItemProcessor에서 REST API를 호출하고 대기하는 시간을 줄이기 위함이다. REST API를 비동기로 사용할 수 있는 다양한 방법 중에서, RestTemplate과 CompletableFuture 조합을 선택한 이유는 추상화 레벨이 낮아서 코드가 직관적이고 예제로 적당하다고 생각한다. 그리고, 파티션의 개수를 더 늘리면 되지 않을까라고 생각할 수도 있지만 단순히 파티션을 늘리면 각 서브 스탭이 가지는 ItemReader, ItemProcessor, ItemWriter 모두 늘어나며 각 스탭이 처리하는 구간이 너무 잘게 나누어진다. 이 예제에서 CompletableFuture를 사용하면서 기대하는 것은 청크 단위에서 각 아이템 처리에 병렬성을 부여하는 것이다.
파티셔너
앞에서 언급했듯이 파티셔닝을 하려면 배치가 커버할 데이터를 나눌 수 있어야 하고, 그 기준을 구현하여 각 서브 스탭이 작업할 구간을 설정해야 한다. job 패키지에 있는 Partitioner 인터페이스를 구현한 RangePartitioner가 이 책임을 가지고 있다. 이 예제의 application.properties 파일에서 PK의 범위를 batch.range.begin, batch.range.end로 설정하고, 몇 개의 파티션을 사용할지를 batch.partition.size로 설정하고 있다. 이 설정값을 기준으로 partition 메서드는 각 서브 스탭이 담당할 구간을 나누어서 설정한다.
RangePartitioner의 단위 테스트 RangePartitionerTest에는 3개의 테스트 시나리오가 있고, 기본적인 동작을 단위 테스트로 확인해 볼 수 있다.
- RangePartitionerTest
- shouldThrowExceptionWhenPartitionSizeIsZeroOrNegative
- shouldHaveEqualRangesForAllPartitions
- shouldHaveOnePartitionWithRangeOneSmaller
여기서 간단히 하나만 보자면, 아래는 shouldHaveEqualRangesForAllPartitions 라는 단위 테스트의 코드다.
@Test
void shouldHaveEqualRangesForAllPartitions() {
// given
final int partitionSize = 3;
// when
final Map<String, ExecutionContext> partitions = partitioner.partition(partitionSize);
// then
final List<ExecutionContext> executionContexts = new ArrayList<>(partitions.values());
long sum = IntStream.range(0, partitionSize)
.mapToObj(executionContexts::get)
.mapToLong(context -> context.getLong("subEnd") - context.getLong("subBegin") + 1)
.sum();
assertEquals(sum, partitioner.getEnd() - partitioner.getBegin() + 1);
}위 테스트는 전체 구간을 3개의 파티션으로 나누었을 때, 나누어진 파티션의 구간의 총합은 전체 구간과 동일해야 한다는 것을 검증한다. 테스트 코드에서 볼 수 있듯이 partition() 함수의 리턴 타입은 ExecutionContext을 값으로 가진 맵이고 이 Context에는 각 서브 스탭이 커버할 구간 정보가 담겨있다. 이 정보는 각 서브 스텝에서 직접 접근하여 읽어온다.
PrepareTasklet의 execute()에서는 아래와 같이 접근한다.
ExecutionContext executionContext =
chunkContext.getStepContext().getStepExecution().getExecutionContext();SourceItemReader의 beforeStep()에서는 아래와 같이 접근한다.
final ExecutionContext executionContext = stepExecution.getExecutionContext();
스레드 풀
이 예제에서 2개의 스레드 풀을 사용한다. 하나는 파티셔너가 각 서브 스탭 실행에 사용할 스레드 풀로 PartitionerTaskExecutor에서 파티션 사이즈로 풀의 크기를 설정하고, 스레드 이름을 설정하는 등의 세부 설정을 위해 별도의 빈으로 구성한다. 나머지 하나는 TransformationItemProcessor가 RestAPI 호출을 비동기로 하기 위해 newFixedThreadPool로 청크 사이즈로 풀의 크기를 설정하고 별도의 설정 없이 간단히 생성한다.
배치 잡 구성
예제에는 DB 초기화와 마이그레이션 대상 데이터를 준비하기 위한 DBInitializerJob과 실제 마이그레이션을 진행할 MigrationJob 이 있다. 이 2개의 잡은 구성이 다르다.
DBInitializerJob
CleanTablesStep과 PrepareDataMainStep으로 구성된 Tasklet 기반으로 청크를 사용하지 않는다. CleanTablesStep은 CleanTablesTasklet을 사용하여 Source와 target DB의 데이터를 삭제하고, PrepareDataMainStep은 PrepareTasklet을 사용하여 Source DB의 마이그레이션에 사용할 Dummy Data를 채운다. 이때, RangePartitioner를 사용하여 girdSize만큼 구간을 나누고 PartitionerTaskExecutor를 사용하여 각 PrepareDataSubStep를 멀티 스레드로 실행한다.
아래는 PrepareDataMainStep의 코드다.
private Step prepareDataMainStep() {
return stepBuilderFactory.get("PrepareDataMainStep")
.allowStartIfComplete(true) // 반복 실행해볼 수 있도록 추가한 설정이다.
.partitioner("PrepareDataSubStep", partitioner) // 여기서 RangePartitioner를 사용하여 구간을 나눈다.
.gridSize(partitionSize)
.taskExecutor(taskExecutor) // 각 스탭이 사용할 스레드 풀을 설정한다.
.step(prepareDataSubStep()) // 각 스레드에서 실행할 스탭을 설정한다.
.build();
}
위에서 설명한 파티셔너와 스레드 풀을 partitioner와 taskExecutor로 주입받고, PrepareDataMainStep에 설정한다. PrepareDataMainStep은 이 두 가지를 활용하여 prepareDataSubStep을 멀티 스레드로 실행한다.
MigrationJob
MigrationJob은 Tasklet 기반 잡과 달리 청크 기반으로 Reader, Processor, Writer 구성을 사용한다.
MigrationJob 구성은 MigrationMainStep 하나로 되어있지만, MigrationMainStep이 파티셔너 설정을 가지면서 MigrationSubStep을 위에서 설명한 것과 같은 방식의 멀티 스레드로 실행한다. MigrationJob이 사용하는 Reader, Processor, Writer의 실제 구성은 MigrationSubStep에 있고, MigrationMainStep은 파티셔너 역할을 한다.
Reader, Processor, Writer의 주요 동작을 하나씩 설명하면, 아래는 SourceItemReader의 read를 구현한 코드다.
@Override
public UserNameEntity read() {
if (nextIdx >= userNameEntities.size()) {
nextIdx = 0;
if (!fetch()) {
log.info("Finished");
return null;
}
}
final UserNameEntity item = userNameEntities.get(nextIdx);
nextIdx++;
return item;
}위 코드에서 read 메서드는 매번 DB에 접근하지 않고 메모리에 캐싱된 데이터가 있는지 확인한다. 캐싱된 데이터가 없다면, 설정된 fetch-size만큼 DB를 조회하여 메모리에 캐싱한다. 이와 같이 read()가 호출될 때마다 DB를 조회하지 않도록 캐싱 방식을 적용하여 DB 접근을 줄이고, fetch-size를 적절히 설정하면서 DB 부하를 조절할 수 있다.
참고로 return userNameEntities.get(nextIdx++); 과 같이 한 줄로 기술할 수 있는 코드를 나누어 쓴 것은 코드의 간결성보다 가독성이 중요하다고 생각하여서다.
TransformationItemProcessor는 위의 '멀티 스레드' 항목에서 설명한 청크 단위에서 각 아이템의 Rest API 호출에 병렬성을 부여하기 위해서 별도의 스레드 풀을 사용한다. 예제의 청크 사이즈는 100으로 설정되어 있고, 스레드 풀의 크기는 아래와 같이 청크 사이즈와 동일하게 설정하고 있다.
public TransformationItemProcessor(NicknameClientService nicknameClientService,
@Value("${batch.chunk-size}") int chunkCount) {
this.nicknameClientService = nicknameClientService;
this.executor = Executors.newFixedThreadPool(chunkCount);
}여기서 헷갈릴 수 있는데, 배치에서 사용하는 전체 스레드 풀의 사이즈가 100이 되는 것은 아니다. 각 파티션마다 MigrationSubStep이 실행된다. 예제의 파티션 사이즈는 10으로 설정되어 있으므로, 10 * 100 해서 전체 스레드 풀의 사이즈는 1000이 된다.
아래는 TransformationItemProcessor의 테스트 코드 중 하나다.
@Test
void testProcessWithNickname() {
// given
final UserNameEntity userNameEntity = new UserNameEntity("user123");
final NicknameResponse response = new NicknameResponse("CoolUser123");
when(nicknameClientService.generateNickname(any(NicknameRequest.class))).thenReturn(response);
// when
final CompletableFuture<UserNameWithNickEntity> result = processor.process(userNameEntity);
// then
assertNotNull(result);
assertEquals("CoolUser123", result.join().getNick(), "The nickname should be 'CoolUser123'");
}위 테스트는 processor가 생성한 Future를 받아서 join()으로 해당 스레드 완료 처리 후의 결과를 확인한다.
아래는 TargetItemWriter의 write를 구현한 코드다.
@Override
public void write(List<? extends CompletableFuture<UserNameWithNickEntity>> items) {
CompletableFuture.allOf(items.toArray(new CompletableFuture[0])).join();
final List<UserNameWithNickEntity> userNameWithNickEntities = items.stream()
.map(future -> future.getNow(null))
.collect(Collectors.toList());
final List<UserNameWithNickEntity> savedItems = targetNickNameRepository.saveAll(userNameWithNickEntities);
log.info("Chunk Finished - saved rows: {}", savedItems.size());
}process가 청크 사이즈만큼 생성한 Future들의 완료 처리를 여기서 대기한다. getNow(null)에서 null이 거슬릴 수도 있지만, 첫 번째 join 호출로 모든 Future가 완료되었으므로 저 null이 리턴될 일은 없다. 단, Future가 예외를 캡처한 상태로 완료된 경우는 캡처된 예외가 여기서 터질 수 있다.
개발하면서 항상 염두에 두는 것이 있는데, 모든 것은 트레이드 오프라는 생각이다. 단순하고 명확한 배치 처리를 하지 않고, 굳이 이렇게 Partitioner와 CompletableFuture를 같이 사용하여 복잡도를 올렸다면 얻는 것이 있어야 한다. 파티션 사이즈와 스레드 풀의 사이즈를 변경하면서 각각의 성능 차이를 확인할 수 있다. 스크린샷은 MySQL Workbench의 Dashboard다. 배치가 DB에 주는 부하 상태를 간단히 확인할 수 있다. 대상 데이터의 크기는 100,000개다.
우선 파티셔너만 사용하는 DBInitializerBatch로 파티션 사이즈를 1, 5, 10, 15로 바꾸면서 성능을 확인하면 아래와 같다. 스크린샷의 대상 DB는 'Source Database - UserNames’다.
batch.partition.size=1
배치 실행 시간: 12s 277ms

batch.partition.size=5
배치 실행 시간: 5s 504ms
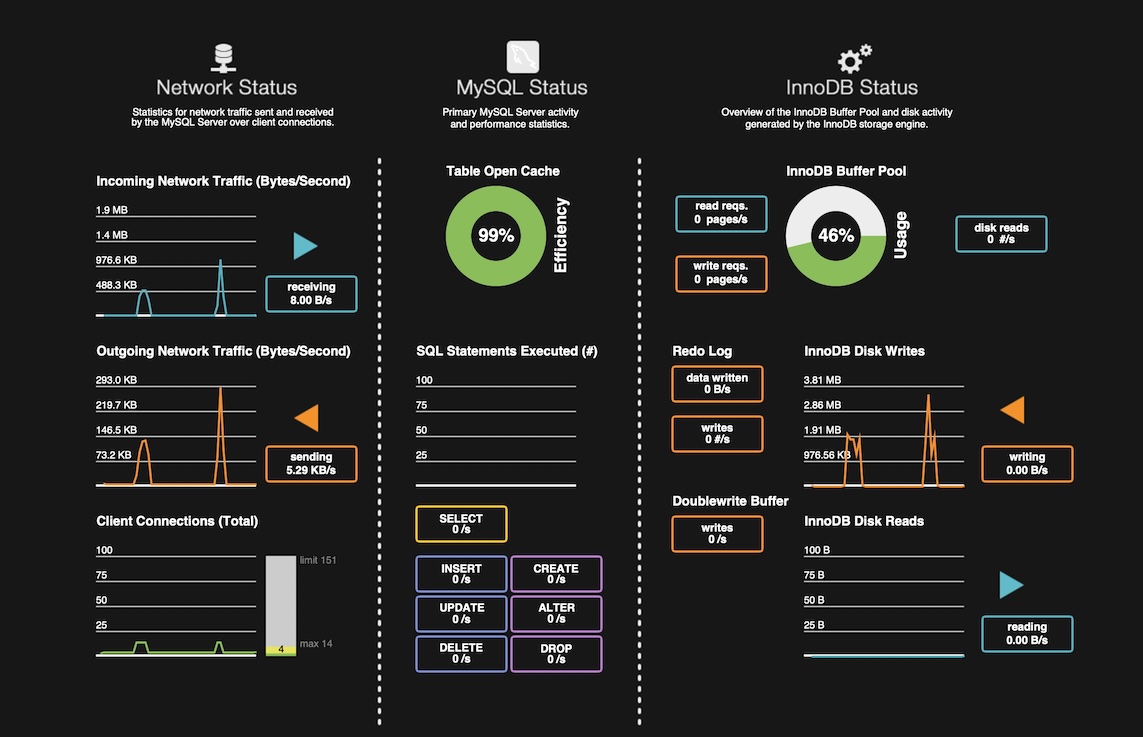
batch.partition.size=10
배치 실행 시간: 4s 718ms
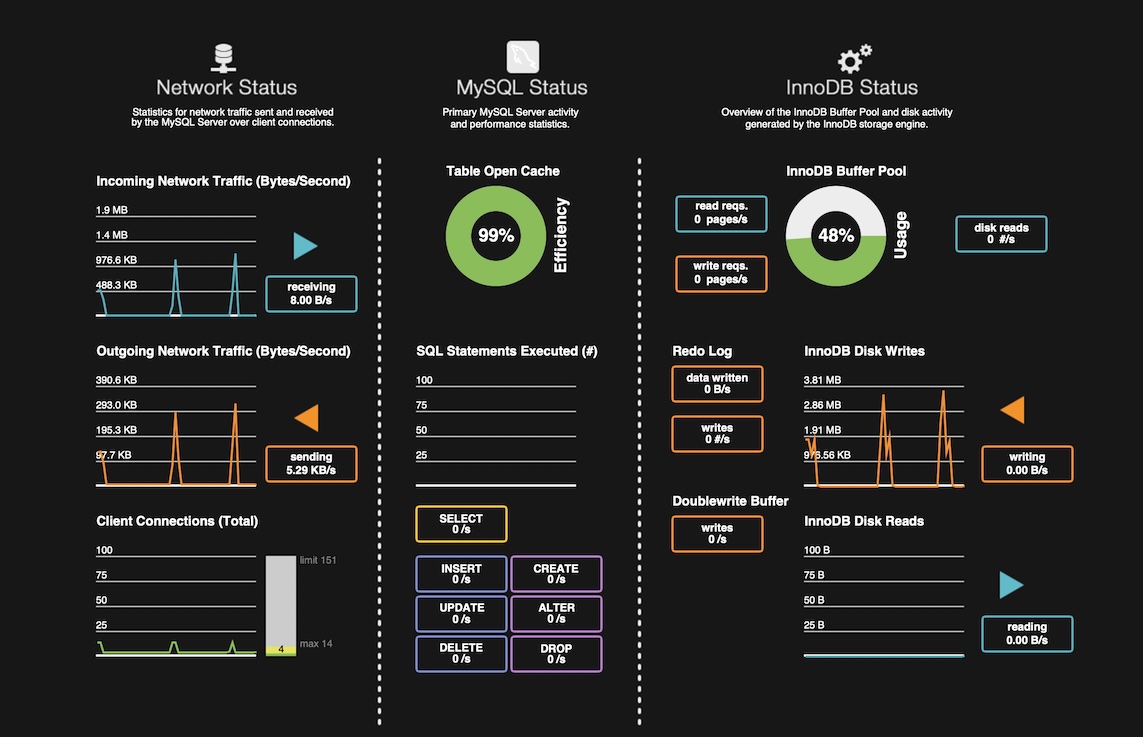
batch.partition.size=15
배치 실행 시간: 5s173ms
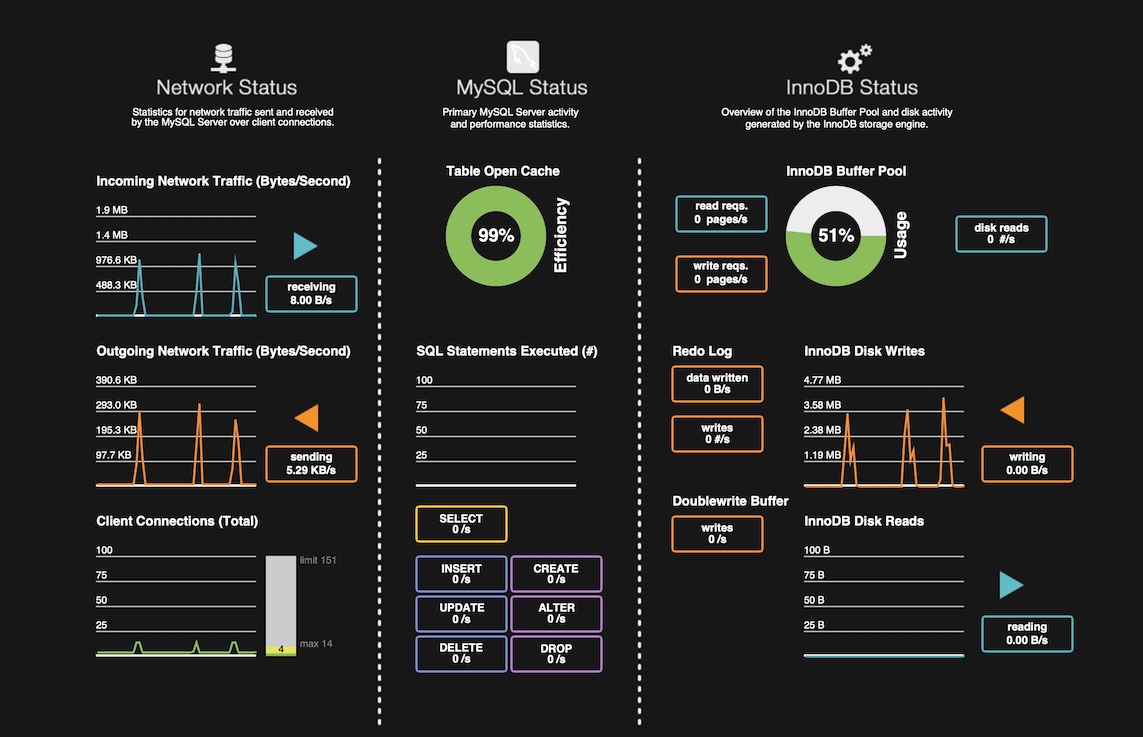
각각의 성능 차이를 보면, 파티션을 크게 설정한다고 무조건 성능이 좋아지는 것은 아니라는 것을 알 수 있다. 배치가 실행되는 환경에 맞는 적절한 설정값을 찾아야 한다. 테스트를 단순하게 하려고 fetch-size와 chunk-size는 고정한 상태로 두었다. 여기서는 파티션 사이즈 5~10 정도에서 좋은 성능을 보여준다.
이제 멀티 스레드로 NicknameGeneratorAPI 서버에 요청을 보내고 응답을 받아서 처리하는 MigrationBatch로 스레드 풀 사이즈는 청크 사이즈와 같은 100 고정이고 파티션 사이즈를 1, 5, 10, 15로 바꾸면서 성능을 확인하면 아래와 같다. 이번 스크린샷의 대상 DB는 'Target Database - Nicknames’다.
batch.partition.size=1
배치 실행 시간: 30s 809ms

batch.partition.size=5
배치 실행 시간: 17s 319ms

batch.partition.size=10
배치 실행 시간: 17s 529ms
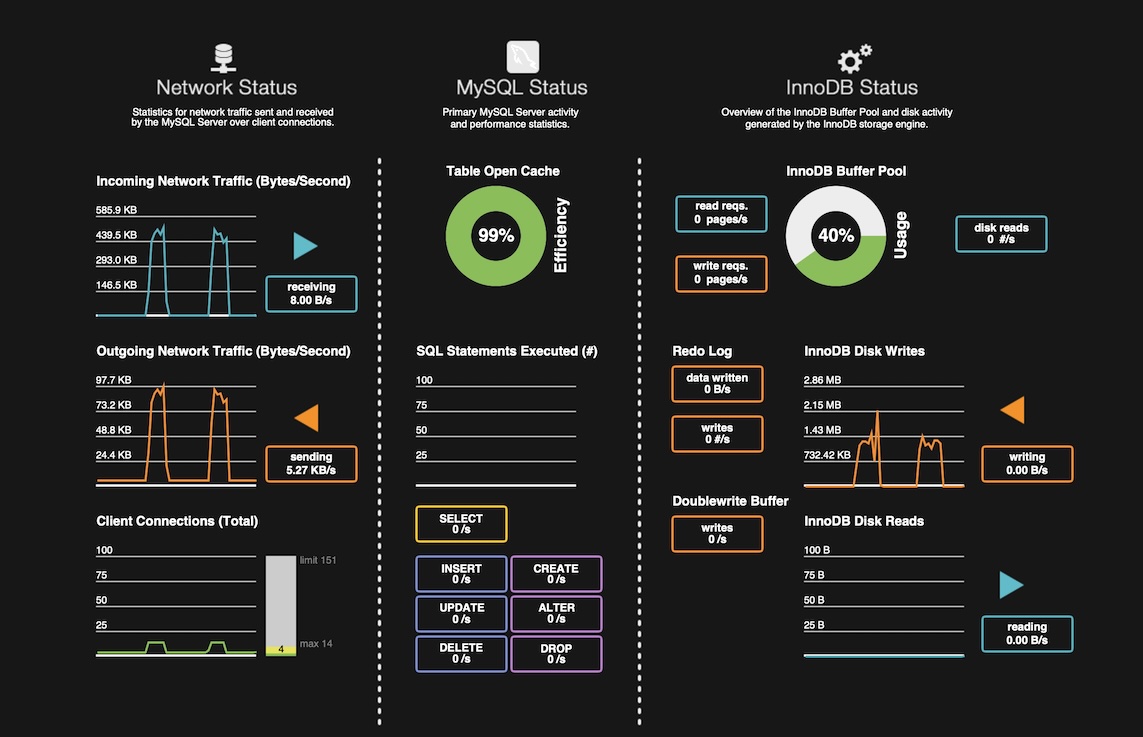
batch.partition.size=15
배치 실행 시간: 17s 529ms

DBInitializerBatch의 성능 결과와 비슷하게 분포되는 것을 알 수 있다. 처리 시간이 전체적으로 증가한 이유는 NicknameGeneratorAPI 서버가 응답 지연 5ms을 강제하고 있어서다. 이제 마지막으로 스레드 풀 사이즈를 1로 낮추어서 성능 차이를 보면 아래와 같다.
batch.partition.size=5 (with thread pool size=1)
배치 실행 시간: 2m 15s 162ms

위에서 스레드 풀 사이즈 낮추기 전의 실행 결과 중에서 파티션 사이즈 5일 때의 실행 시간이 17초인데 방금 확인한 2분 15초는 매우 큰 성능 차이가 생긴 것을 알 수 있다. 이 성능 차이로 파티셔너를 사용하면서도 멀티 스레드로 API의 응답 지연을 커버하는 것이 성능 개선에 도움이 된다는 것을 알 수 있다. 이 정도면 복잡도 증가와 성능 개선의 트레이드오프를 할 만한 가치가 있다고 생각한다.
마치며
지금까지 설명한 부분은 스프링 배치에서 Partitioner와 CompletableFuture의 조합으로 하나의 JVM으로 더 효율적인 배치를 실행하는 방법의 하나다. 예제의 코드 구성에서 설명하지 않은 부분이 많지만, 이 글의 도입부에서 언급했듯이 모든 내용을 하나의 포스팅으로 정리하기에는 예제를 너무 크게 만들었다. 여기서 다루지 않은 내용은 다음 기회로 남긴다. 글을 마무리하면서 참고했던 책을 하나 소개한다.
스프링 배치 완벽 가이드 2/e
스프링 배치의 새로운 버전이 이미 나온 상황이라 이 책은 이제 구버전을 다루고 있지만, 스프링 배치를 다룬 책이 달리 없고 책의 내용도 좋다.
https://www.aladin.co.kr/shop/wproduct.aspx?ItemId=269630446
스프링 배치 완벽 가이드 2/e
스프링 배치의 Hello, World!부터 최근 플랫폼의 발전에 따른 클라우드 네이티브 기술을 활용한 배치까지 폭넓은 스프링 배치 활용 방법과 이와 관련된 유용한 내용을 다룬다.
www.aladin.co.kr
'Dev' 카테고리의 다른 글
| Spring의 ConcurrentWebSocketSessionDecorator 소개 (1) | 2025.04.28 |
|---|---|
| IntelliJ의 Groovy Console 소개 (1) | 2025.03.04 |
| 가상 면접 사례로 배우는 대규모 시스템 설계 기초 2 (0) | 2024.03.16 |
| 진화적 아키텍처 (0) | 2023.09.24 |
| 자바 알고리즘 인터뷰 with 코틀린 - 102가지 알고리즘 문제 풀이로 완성하는 코딩 테스트 (0) | 2023.09.14 |